
Redis设计与实现之对象
对象的类型与编码
对象
- Redis 使用
对象来表示数据库中的键和值 - 在 Redis 的数据库中新创建一个键值对时, 我们至少会创建两个对象, 一个对象用作键值对的键(键对象), 另一个对象用作键值对的值(值对象)。
对象的数据结构
代码位置 : server.h
typedef struct redisObject {
unsigned type:4; //4位记录数据类型
unsigned encoding:4; //4位记录编码方式
unsigned lru:LRU_BITS; //表示对象最后一次被命令程序访问的时间
int refcount; //引用计数
void *ptr; //实际存储数据的指针
} robj;type: 4位记录数据类型encoding: 4位记录编码方式lru: 表示对象最后一次被命令程序访问的时间refcount: 引用计数*ptr: 实际存储数据的指针
对象类型
对象的 type 属性记录了对象的类型, 这个属性的值可以是如下值:
REDIS_STRING : 字符串对象
REDIS_LIST : 列表对象
REDIS_HASH : 哈希对象
REDIS_SET : 集合对象
REDIS_ZSET : 有序集合对象
对于 Redis 数据库保存的键值对来说,键总是一个字符串对象, 而值则可以是 上述的任何一种,因此,有如下说法:
- 当我们称呼一个数据库键为“字符串键”时, 我们指的是“这个数据库键所对应的值为字符串对象”
- 当我们称呼一个键为“列表键”时, 我们指的是“这个数据库键所对应的值为列表对象”
- 使用
type命令可查看一个键对应的值的数据类型
对象类型示例
redis-cli
127.0.0.1:6379> set msg "hello world"
OK
127.0.0.1:6379> type msg
string
127.0.0.1:6379> rpush numList 1 3 5
(integer) 3
127.0.0.1:6379> type numList
list
127.0.0.1:7379> hmset people name zhangdeman birth 1996-01
OK
127.0.0.1:6379> type people
hash
127.0.0.1:6379> sadd fruits apple branna cherry
(integer) 3
127.0.0.1:6379> type fruits
set
127.0.0.1:6379> zadd price 8.5 apple 5.0 banana 6.0 cherry
(integer) 3
127.0.0.1:6379> type price
zset
127.0.0.1:6379>]对象编码与实现
对象的 ptr 指针 指向对象的底层实现数据结构, 而这些数据结构由对象的 encoding 属性决定。
对象编码列表
| 编码常量 | 编码所对应的底层数据结构 |
|---|---|
| REDIS_ENCODING_INT | long 类型的整数 |
| REDIS_ENCODING_EMBSTR | embstr 编码的简单动态字符串 |
| REDIS_ENCODING_RAW | 简单动态字符串 |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ENCODING_LINKEDLIST | 双端链表 |
| REDIS_ENCODING_ZIPLIST | 压缩列表 |
| REDIS_ENCODING_INTSET | 整数集合 |
| REDIS_ENCODING_SKIPLIST | 跳跃表和字典 |
每种类型的对象都至少使用了两种不同的编码, 下表为不同类型和编码的对象 :
| 类型 | 编码 | 对象 |
|---|---|---|
| REDIS_STRING | REDIS_ENCODING_INT | 使用整数值实现的字符串对象。 |
| REDIS_STRING | REDIS_ENCODING_EMBSTR | 使用 embstr 编码的简单动态字符串实现的字符串对象。 |
| REDIS_STRING | REDIS_ENCODING_RAW | 使用简单动态字符串实现的字符串对象。 |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的列表对象。 |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST | 使用双端链表实现的列表对象。 |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的哈希对象。 |
| REDIS_HASH | REDIS_ENCODING_HT | 使用字典实现的哈希对象。 |
| REDIS_SET | REDIS_ENCODING_INTSET | 使用整数集合实现的集合对象。 |
| REDIS_SET | REDIS_ENCODING_HT | 使用字典实现的集合对象。 |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的有序集合对象。 |
| REDIS_ZSET | REDIS_ENCODING_SKIPLIST | 使用跳跃表和字典实现的有序集合对象。 |
使用 OBJECT ENCODING 命令 可以查看一个数据库键的值对象的编码, 下表为对不同编码的输出 :
| 对象所使用的底层数据结构 | 编码常量 | OBJECT ENCODING 命令输出 |
|---|---|---|
| 整数 | REDIS_ENCODING_INT | "int" |
| embstr | 编码的简单动态字符串(SDS) REDIS_ENCODING_EMBSTR | "embstr" |
| 简单动态字符串 | REDIS_ENCODING_RAW | "raw" |
| 字典 | REDIS_ENCODING_HT | "hashtable" |
| 双端链表 | REDIS_ENCODING_LINKEDLIST | "linkedlist" |
| 压缩列表 | REDIS_ENCODING_ZIPLIST | "ziplist" |
| 整数集合 | REDIS_ENCODING_INTSET | "intset" |
| 跳跃表和字典 | REDIS_ENCODING_SKIPLIST | "skiplist" |
【知识点】 不为特定类型的对象关联一种固定的编码, 极大地提升了 Redis 的
灵活性和效率, 因为 Redis 可以根据不同的使用场景来为一个对象设置不同的编码, 从而优化对象在某一场景下的效率 一个效率优化的例子: 列表对象包含的元素比较少时, Redis 使用压缩列表作为列表对象的底层实现,因为压缩列表比双端链表更节约内存, 并且在元素数量较少时, 在内存中以连续块方式保存的压缩列表比起双端链表可以更快被载入到缓存中随着列表对象包含的元素越来越多, 使用压缩列表来保存元素的优势逐渐消失时, 对象就会将底层实现从压缩列表转向功能更强、也更适合保存大量元素的双端链表上面
字符串对象
字符串对象的编码
int
如果一个字符串对象保存的是 整数值 , 并且这个整数值可以用 long 类型来表示, 那么字符串对象会将整数值保存在字符串对象结构的 ptr 属性里面(将 void* 转换成 long ), 并将字符串对象的编码设置为 int ,举例如下:
设置数据
redis-cli
127.0.0.1:6379> set num 10080
OK
127.0.0.1:6379> object encodeing num
"int"
127.0.0.1:6379>]int编码字符串存储结构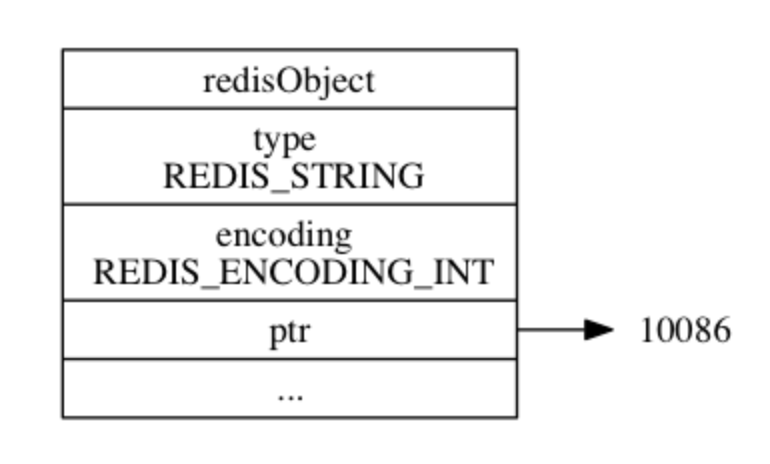
raw
如果字符串对象保存的是一个字符串值, 并且这个字符串值的 长度大于 39 字节 , 那么字符串对象将使用一个 简单动态字符串(SDS) 来保存这个字符串值, 并将对象的编码设置为 raw , 举例如下:
redis-cli
127.0.0.1:6379> set story "Long, long, long ago there lived a king ..."
OK
127.0.0.1:6379> strlen story
(integer) 43
127.0.0.1:6379> object encoding story
"raw"
127.0.0.1:6379>]raw编码字符串存储结构
embstr
embstr 编码是 专门用于保存短字符串 的一种优化编码方式, 用于存储短字符串 
【知识点】 embstr 和 raw 编码一样, 都使用
redisObject 结构和 sdshdr 结构来表示字符串对象 raw 编码会调用两次内存分配函数来分别创建 redisObject 结构和 sdshdr 结构 embstr 编码则通过调用一次内存分配函数来分配一块连续的空间, 空间中依次包含 redisObject 和 sdshdr 两个结构,比起 raw 编码的字符串对象能够更好地利用缓存带来的优势。
字符串对象保存各类型值的编码方式
| 值 | 编码 |
|---|---|
| 可以用 long 类型保存的整数。 | int |
| 可以用 long double 类型保存的浮点数。 | embstr 或者raw |
| 字符串值 因为长度太大而没办法用 long 类型表示的整数 因为长度太大而没办法用 long double 类型表示的浮点数。 | embstr 或者raw |
编码的转换
- int 编码的字符串对象, 如果我们向对象执行了一些命令, 使得这个对象保存的
不再是整数值, 而是一个字符串值, 那么字符串对象的编码将从 int 变为 raw 。 - embstr 编码的字符串对象在执行修改命令之后, 总会变成一个 raw 编码的字符串对象。
【知识点】 Redis 没有为 embstr 编码的字符串对象编写任何相应的修改程序 (只有 int 编码的字符串对象和 raw 编码的字符串对象有这些程序), 所以 embstr 编码的字符串对象实际上是只读的: 当我们对 embstr 编码的字符串对象执行任何修改命令时, 程序会先将对象的编码从 embstr 转换成 raw , 然后再执行修改命令; 因为这个原因, embstr 编码的字符串对象在执行修改命令之后, 总会变成一个 raw 编码的字符串对象。
列表对象
列表对象的编码
ziplist 、 linkedlist
ziplist编码
ziplist 编码的列表对象使用 压缩列表 作为底层实现, 每个压缩列表节点(entry)保存了一个列表元素。压缩列表原理参见:压缩列表原理与实现.示例如下:
操作命令
redis-cli
127.0.0.1:6379> rpush numbers 1 "three" 5
(integer) 3
127.0.0.1:6379>]存储结构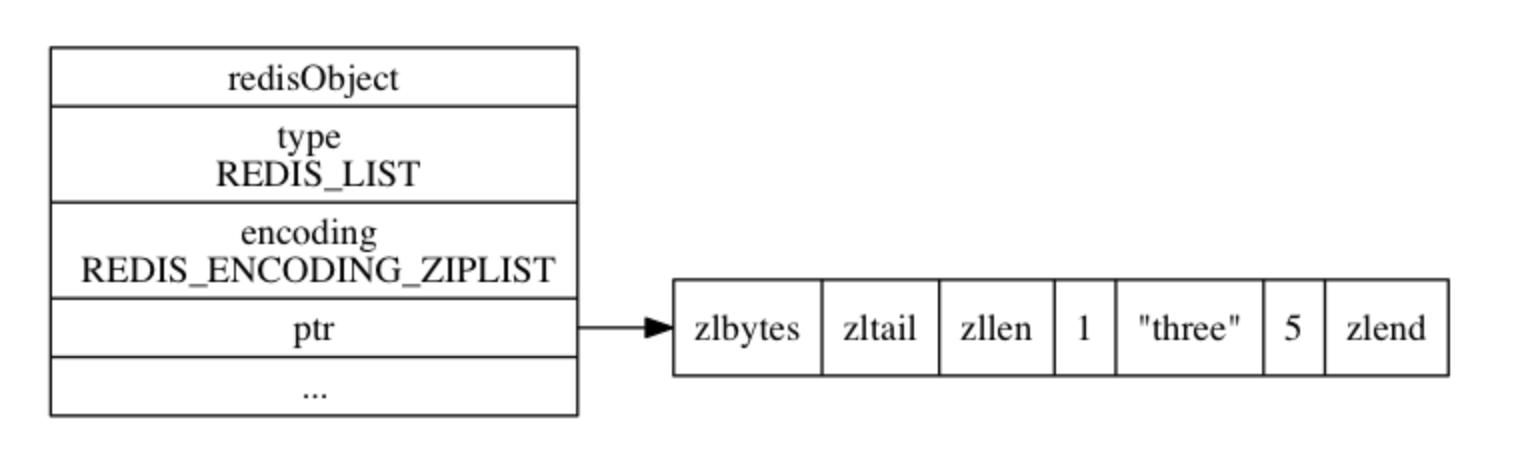
linkedlist编码
linkedlist 编码的列表对象使用 双端链表 作为底层实现, 每个双端链表节点(node)都保存了一个字符串对象, 而每个字符串对象都保存了一个列表元素。依旧以上述操作为例,假设numbers使用的存储结构为双端列表,则存储结构如下:
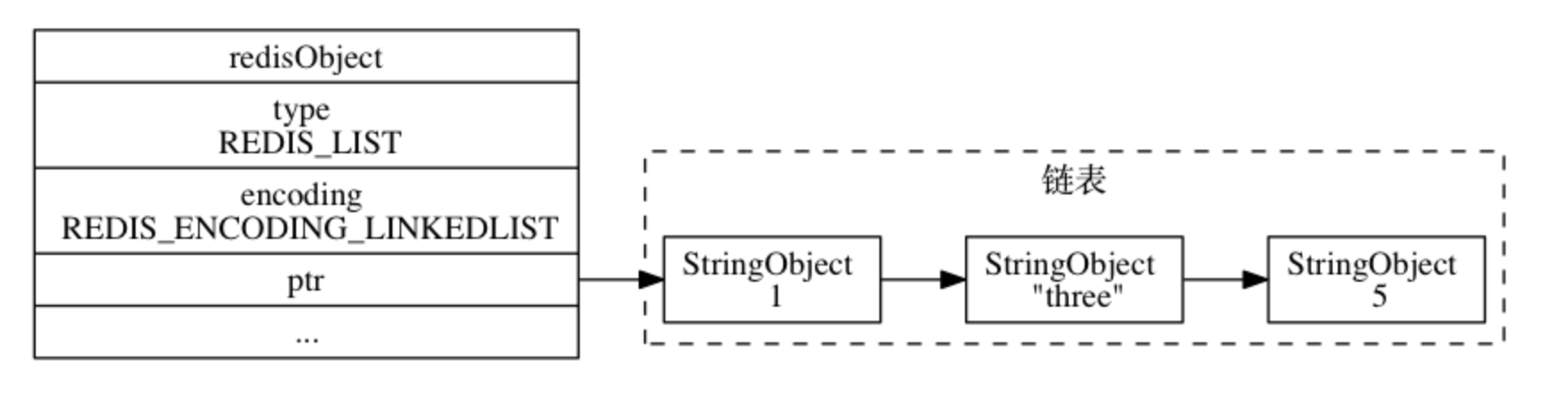
【知识点】 linkedlist 编码的列表对象在底层的双端链表结构中包含了多个字符串对象,字符串对象是 Redis 五种类型的对象中
唯一一种会被其他四种类型对象嵌套的对象。 为简化表示,图示中使用了stringObject来表示字符串对象,实际字符串对象结构如下:

编码转换
列表对象使用 ziplist 编码的条件
- 列表对象保存的所有字符串
元素的长度都小于 64 字节 - 列表对象保存的
元素数量小于 512 个
当上述两个条件任意一个不被满足时,编码将会被转化为 linkedlist
【知识点】 元素的最大程度是可配置的,配置项为:
list-max-ziplist-value列表保存的元素数量也是可配置的,配置项为:list-max-ziplist-entries
hash对象
哈希对象的编码
ziplist 、 hashtable
ziplist 编码
ziplist 编码的哈希对象使用 压缩列表 作为底层实现, 每当有新的键值对要加入到哈希对象时, 程序会先将保存了键的压缩列表节点推入到压缩列表表尾, 然后再将保存了值的压缩列表节点推入到压缩列表表尾,因此有如下特点:
- 保存了同一键值对的两个节点总是紧挨在一起, 保存键的节点在前, 保存值的节点在后
- 先添加到哈希对象中的键值对会被放在压缩列表的表头方向, 而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向 具体示例如下:
redis-cli
127.0.0.1:6379> HSET profile name TOM
(integer) 1
HSET profile age 25
(integer) 1
127.0.0.1:6379> HSET profile career Programmer
(integer) 1
127.0.0.1:6379>]哈希对象存储结构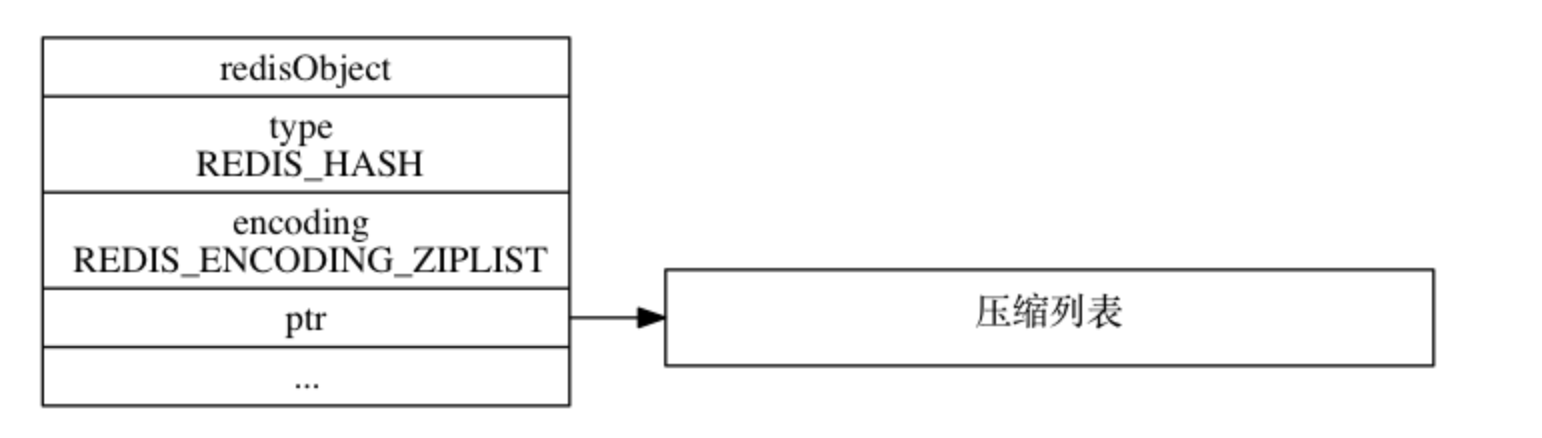
压缩列表存储结构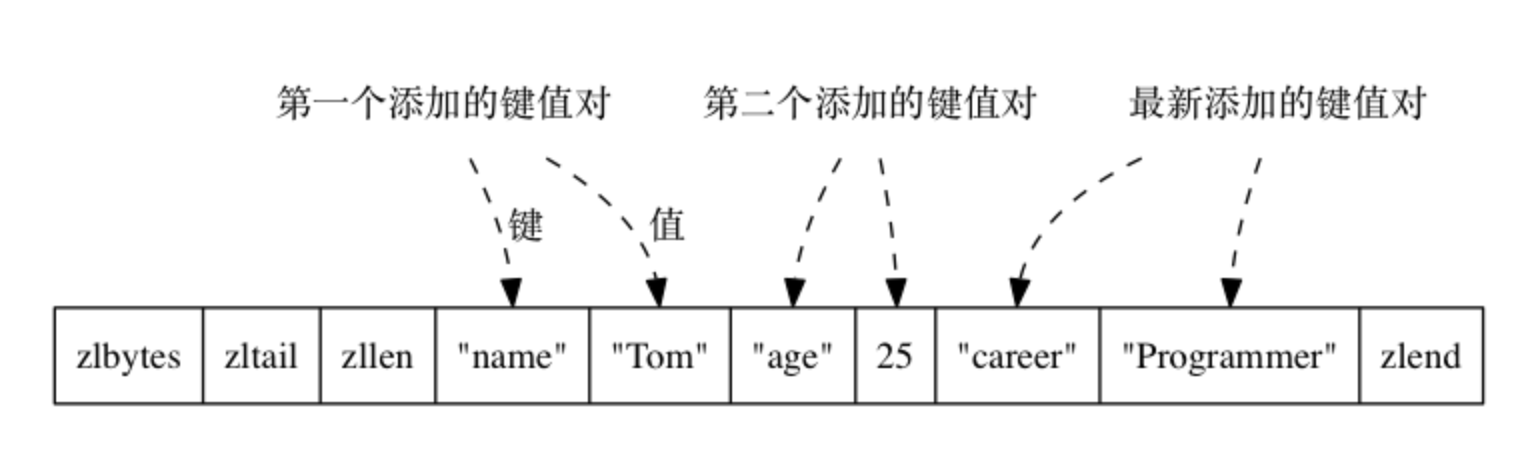
hashtable 编码
hashtable 编码的哈希对象使用 字典 作为底层实现, 哈希对象中的每个键值对都使用一个字典键值对来保存, 字典的原理与实现参见: 字典的原理与实现
- 字典的每个键都是一个字符串对象, 对象中保存了键值对的键
- 字典的每个值都是一个字符串对象, 对象中保存了键值对的值
依旧以上述操作为例,hashtable编码,存储结构如下:
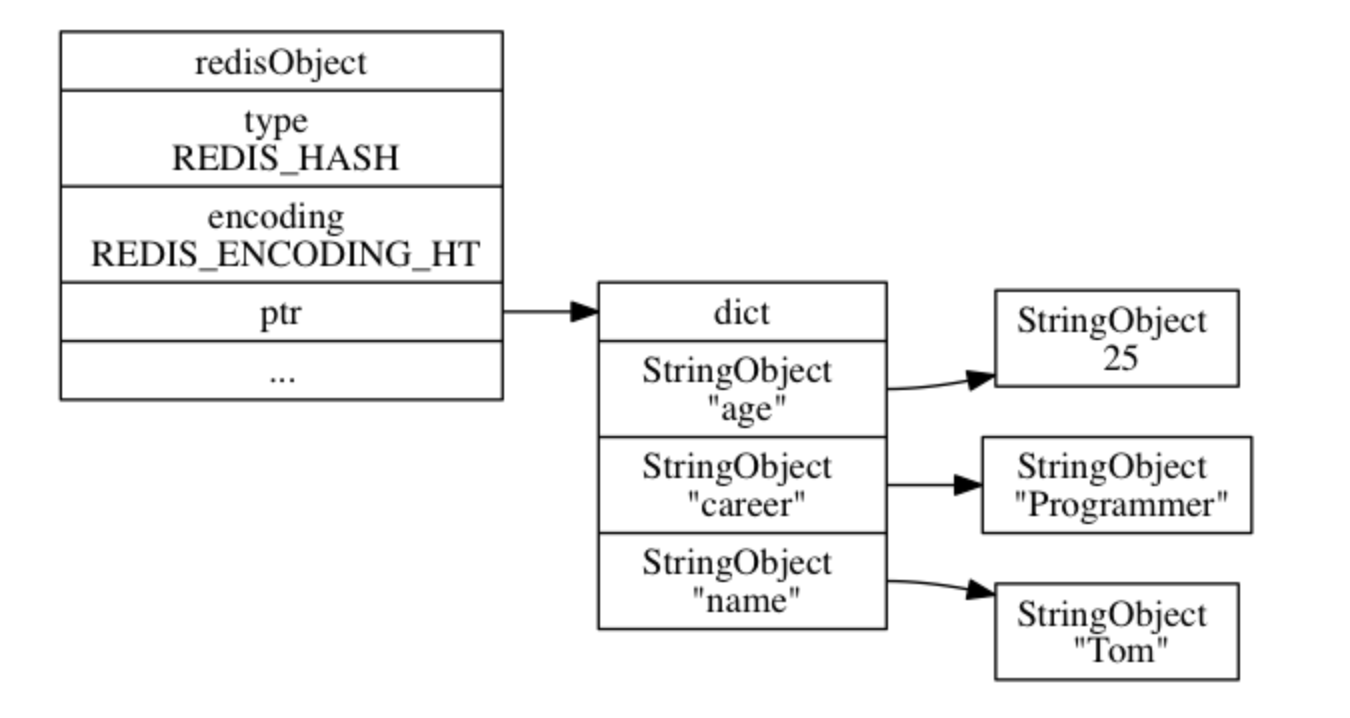
编码转换
哈希对象使用 ziplist 编码的条件
- 列表对象保存的所有字符串
元素的长度都小于 64 字节 - 列表对象保存的
元素数量小于 512 个
当上述两个条件任意一个不被满足时,编码将会被转化为 hashtable
【知识点】 元素的最大程度是可配置的,配置项为:
list-max-ziplist-value
列表保存的元素数量也是可配置的,配置项为:
list-max-ziplist-entries
集合对象
集合对象的编码
intset、hashtable
intset编码
intset 编码的集合对象使用 整数集合 作为底层实现, 集合对象包含的所有元素都被保存在整数集合里面。
redis-cli
127.0.0.1:6379> SADD numbers 1 3 5
(integer) 3
127.0.0.1:6379>]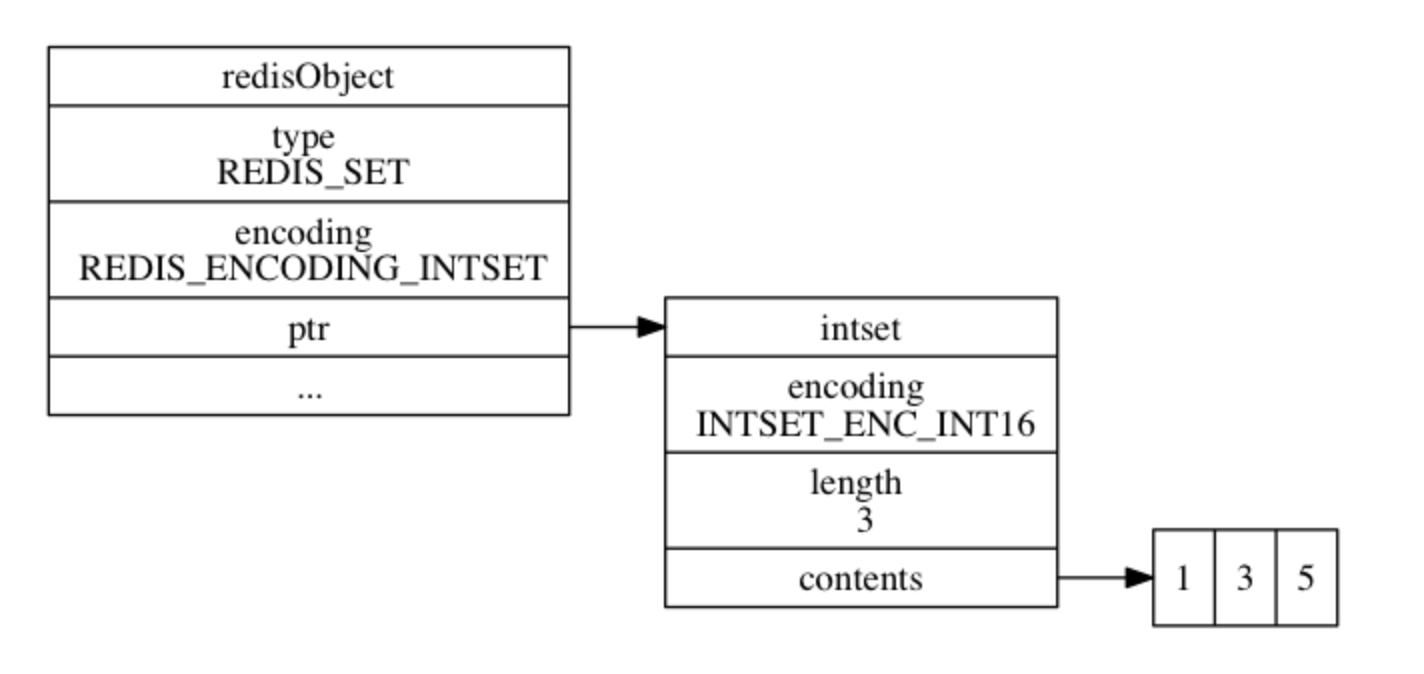
hashtable编码
hashtable 编码的集合对象使用 字典 作为底层实现, 字典的 每个键 都是一个 字符串对象 , 每个字符串对象包含了一个集合元素, 而字典的 值 则全部被设置为 NULL 。具体例子如下:
redis-cli
127.0.0.1:6379> SADD fruits "apple" "banana" "cherry"
(integer) 3
127.0.0.1:6379>]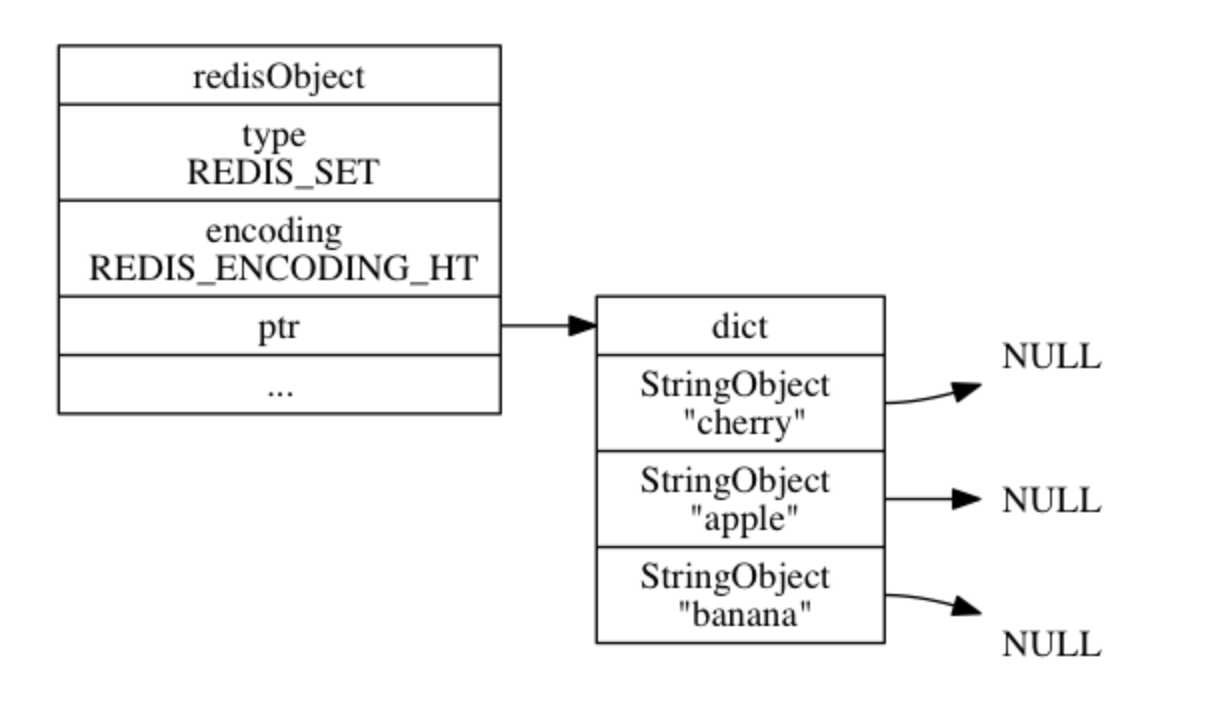
编码转换
使用 intset 编码的条件
- 集合对象保存的
所有元素都是整数值 - 集合对象保存的元素数量
不超过 512 个 - 对于使用 intset 编码的集合对象来说,以上两个条件的任意一个不能被满足时, 对象的编码转换操作就会被执行:原本保存在整数集合中的所有元素都会被转移并保存到字典里面, 并且对象的编码也会从 intset 变为 hashtable 。
【知识点】 集合对象保存的元素数量的上限是可配置的,具体配置项为: set-max-intset-entries
有序集合对象
有序集合编码
ziplist 、skiplist
ziplist 编码
ziplist 编码的有序集合对象使用压缩列表作为底层实现, 每个集合元素使用两个紧挨在一起的压缩列表节点来保存, 第一个节点保存元素的成员(member), 而第二个元素则保存元素的分值(score)。
压缩列表内的集合元素按分值从小到大进行排序, 分值较小的元素被放置在靠近表头的方向, 而分值较大的元素则被放置在靠近表尾的方向。 aiplist的实现参见:压缩列表原理与实现 具体例子如下:
redis-cli
127.0.0.1:6379> zadd price 8.5 apple 5.0 banana 6.0 cherry
(integer) 3
127.0.0.1:6379>]有序集合对象存储结构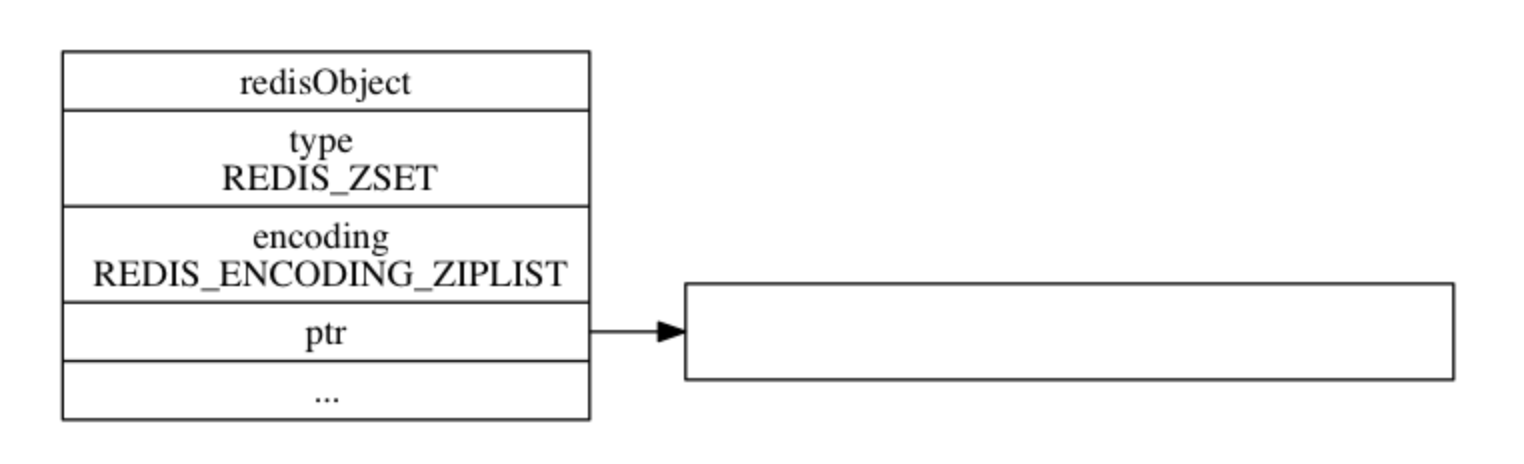
有序集合元素在压缩列表中的排列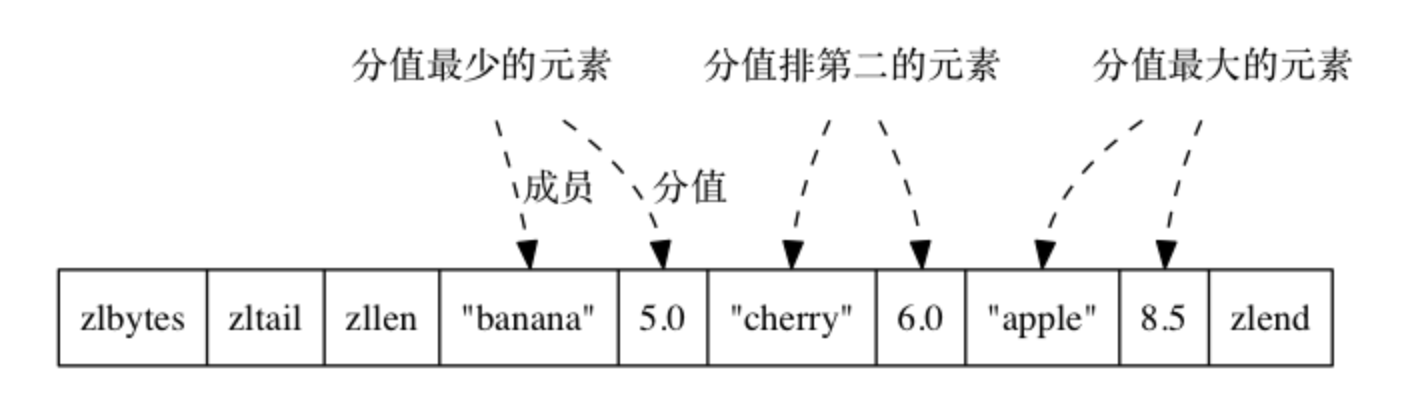
skiplist 编码
skiplist 编码的有序集合对象使用 zset 结构作为底层实现, 一个 zset 结构同时包含 一个字典和一个跳跃表 :
typedef struct zset {
zskiplist *zsl;
dict *dict;
} zset;- zsl 跳跃表 按分值从小到大 保存了所有集合元素, 每个跳跃表节点都保存了一个集合元素
- 跳跃表节点的 object 属性保存了元素的成员, 而跳跃表节点的 score 属性则保存了元素的分值
- 通过这个跳跃表, 程序可以对有序集合进行 范围型操作, 比如 ZRANK 、 ZRANGE 等命令就是基于跳跃表 API 来实现的
- dict 字典为有序集合创建了一个从 成员到分值 的映射, 字典中的 每个键值对 都保存了一个集合元素
- 字典的 键 保存了元素的 成员, 而字典的 值 则保存了元素的 分值
- 通过这个字典, 程序可以用 O(1) 复杂度查找给定成员的分值, ZSCORE 命令就是根据这一特性实现的, 而很多其他有序集合命令都在实现的内部用到了这一特性
- 有序集合每个元素的 成员 都是一个 字符串对象, 而每个元素的 分值 都是一个 double 类型的浮点数
以上述price为例,如果不是使用ziplist编码存储,而是使用skiplist编码存储,则其存储结构如下所示:

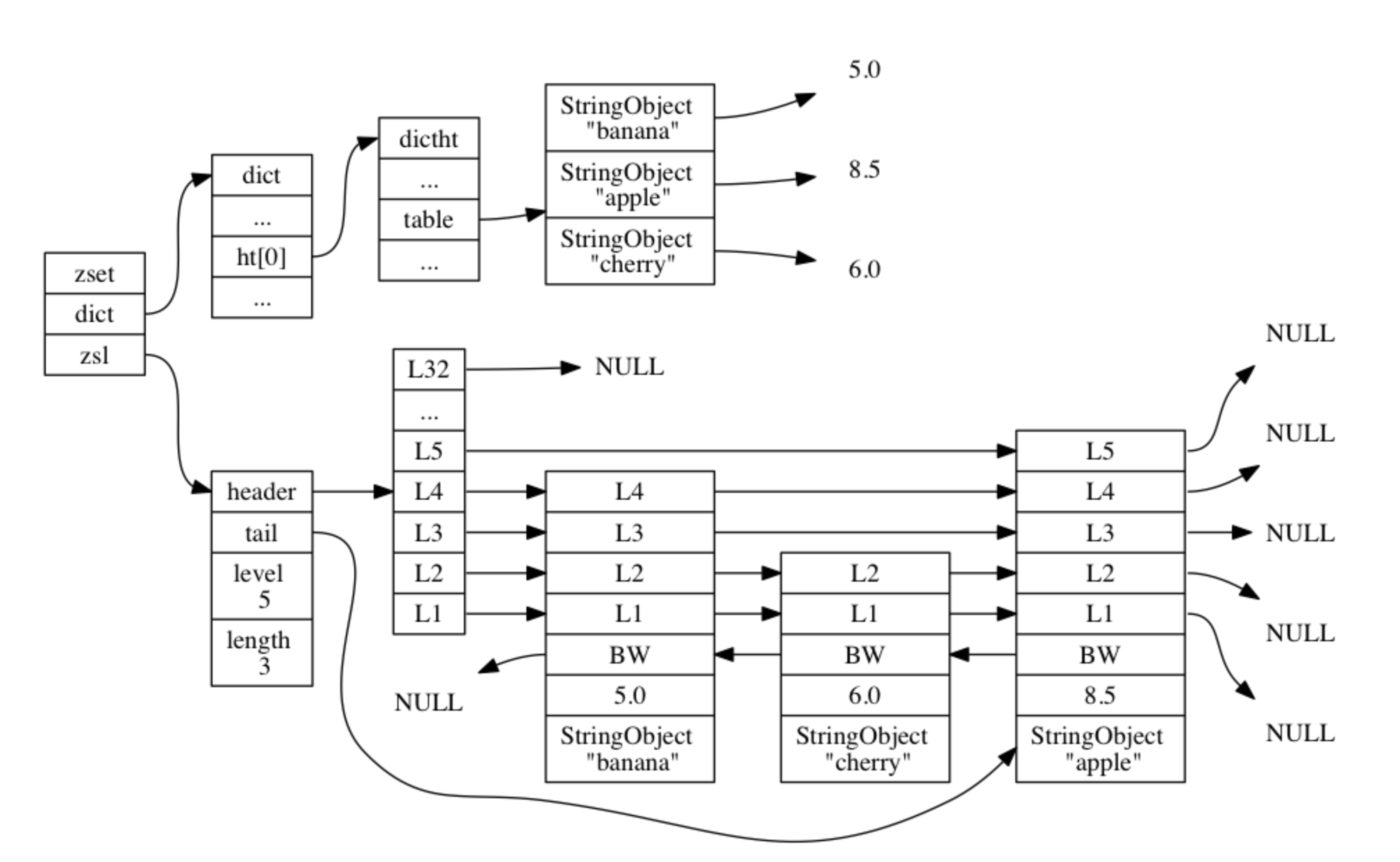
【知识点】 为解释方便,上图在字典和跳跃表中重复展示了各个元素的成员和分值. 虽然 zset 结构同时使用跳跃表和字典来保存有序集合元素, 但这两种数据结构都会通过指针来 共享相同元素的成员和分值, 所以同时使用跳跃表和字典来保存集合元素 不会产生任何重复成员或者分值, 也不会因此而浪费额外的内存。
为什么有序集合需要同时使用跳跃表和字典来实现?
在理论上来说, 有序集合可以单独使用字典或者跳跃表的其中一种数据结构来实现, 但无论单独使用字典还是跳跃表, 在对比起同时使用字典和跳跃表 性能上都会有所降低。
如果我们只使用字典来实现有序集合, 那么虽然以 O(1) 复杂度查找成员的分值这一特性会被保留, 但是, 因为字典以无序的方式来保存集合元素, 所以每次在执行范围型操作 —— 比如 ZRANK 、 ZRANGE 等命令时, 程序都需要对字典保存的所有元素进行排序, 完成这种排序需要至少 O(N * log N) 时间复杂度, 以及额外的 O(N) 内存空间 (因为要创建一个数组来保存排序后的元素)。
另一方面, 如果我们只使用跳跃表来实现有序集合, 那么跳跃表执行范围型操作的所有优点都会被保留, 但因为没有了字典, 所以根据成员查找分值这一操作的复杂度将从 O(1) 上升为 O(log N) 。
因为以上原因, 为了让有序集合的查找和范围型操作都尽可能快地执行, Redis 选择了同时使用字典和跳跃表两种数据结构来实现有序集合。
编码转换
使用 ziplist 编码的条件
- 有序集合保存的元素数量 小于 128 个
- 序集合保存的所有元素成员的长度都 小于 64 字节
- 以上两个条件中的任意一个不能被满足时, 程序就会执行编码转换操作, 将原本储存在压缩列表里面的所有集合元素转移到 zset 结构里面, 并将对象的编码从 ziplist 改为 skiplist
【知识点】 保存的元素数量是可修改的,具体配置项为:
zset-max-ziplist-entries单元素成员的长度是可修改的,具体配置项为:zset-max-ziplist-value
参考资料
参考资料
参考内容
书籍 : 《Redis 设计与实现》
实体书 : 可在京东搜索购买
注意事项
《Redis 设计与实现》 本书讲解基于redis 3.x 版本, 本人整理基于redis 5.0.6,期间跨了两个大版本, 部分功能具体实现已发生变化, 如发现整理内容与 《Redis 设计与实现》 讲解不一致, 可加 QQ : 2215508028 沟通,或在相关章节评论留言,会自动同步至issue
整理内容时参考的redis源码
版本 : 5.0.6
官方git : redis官方GIT (commit :bb78454b0fef0dc5903328d037ac2520108e0044 (5.0.6版本,redis官方的commit))