
开闭原则
定义
开闭原则(The Open-Close Principle,OCP) 中,“开”指的是对扩展开放,“闭”指的是对修改封闭,它的完整解释为:
A software artifact should be open for extension but closed for modification.
通俗地讲就是:一个软件系统应该具备良好的可扩展性,新增功能应当通过扩展的方式实现,而不是在已有的代码基础上修改 。
关键点
从字面意思上看,OCP貌似又是自相矛盾的:想要给一个模块新增功能,但是又不能修改它。
如何才能打破这个困境呢?关键是 抽象 !优秀的软件系统总是建立在良好的抽象的基础上,抽象化可以降低软件系统的复杂性。
抽象的过程
那么什么是抽象呢?抽象不仅存在于软件领域,在我们的生活中也随处可见。下面以《语言学的邀请》中的一个例子来解释抽象的含义:
假设某农庄有一头叫“阿花”的母牛,那么:
1、当把它称为“阿花”时,我们看到的是它独一无二的一些特征:身上有很多斑点花纹、额头上还有一个闪电形状的伤疤。
2、当把它称为母牛时,我们忽略了它的独有特征,看到的是它与母牛“阿黑”,母牛“阿黄”的共同点:是一头牛、雌性的。
3、当把它称为家畜时,我们又忽略了它作为母牛的特征,而是看到了它和猪、鸡、羊一样的特点:是一个动物,在农庄里圈养。
4、当把它称为农庄财产时,我们只关注了它和农庄上其他可售对象的共同点:可以卖钱、转让。
从“阿花”,到母牛,到家畜,再到农庄财产,这就是 一个不断抽象化的过程 。
从上述例子中,我们可以得出这样的结论:
- 抽象就是
不断忽略细节,找到事物间共同点的过程。 - 抽象是
分层的,抽象层次越高,细节也就越少。
具体示例
开闭原则
抽象的基础是接口
再回到软件领域,我们也可以把上述的例子类比到数据库上,数据库的抽象层次从低至高可以是这样的:MySQL 8.0版本 -> MySQL -> 关系型数据库 -> 数据库。现在假设有一个需求,需要业务模块将业务数据保存到数据库上,那么就有以下几种设计方案:
- 方案一:把业务模块设计为直接依赖MySQL 8.0版本。因为版本总是经常变化的,如果哪天MySQL升级了版本,那么我们就得修改业务模块进行适配,所以方案一违反了OCP。
- 方案二:把业务模块设计为依赖MySQL。相比于方案一,方案二消除了MySQL版本升级带来的影响。现在考虑另一种场景,如果因为某些原因公司禁止使用MySQL,必须切换到PostgreSQL,这时我们还是得修改业务模块进行数据库的切换适配。因此,在这种场景下,方案二也违反了OCP。
- 方案三:把业务模块设计为依赖关系型数据库。到了这个方案,我们基本消除了关系型数据库切换的影响,可以随时在MySQL、PostgreSQL、Oracle等关系型数据库上进行切换,而无须修改业务模块。但是,熟悉业务的你预测未来随着用户量的迅速上涨,关系型数据库很有可能无法满足高并发写的业务场景,于是就有了下面的最终方案。
- 方案四:把业务模块设计为依赖数据库。这样,不管以后使用MySQL还是PostgreSQL,关系型数据库还是非关系型数据库,业务模块都不需要再改动。到这里,我们基本可以认为业务模块是稳定的,不会受到底层数据库变化带来的影响,满足了OCP。
我们可以发现,上述方案的演进过程,就是我们不断对业务依赖的数据库模块进行抽象的过程,最终设计出稳定的、服务OCP的软件。
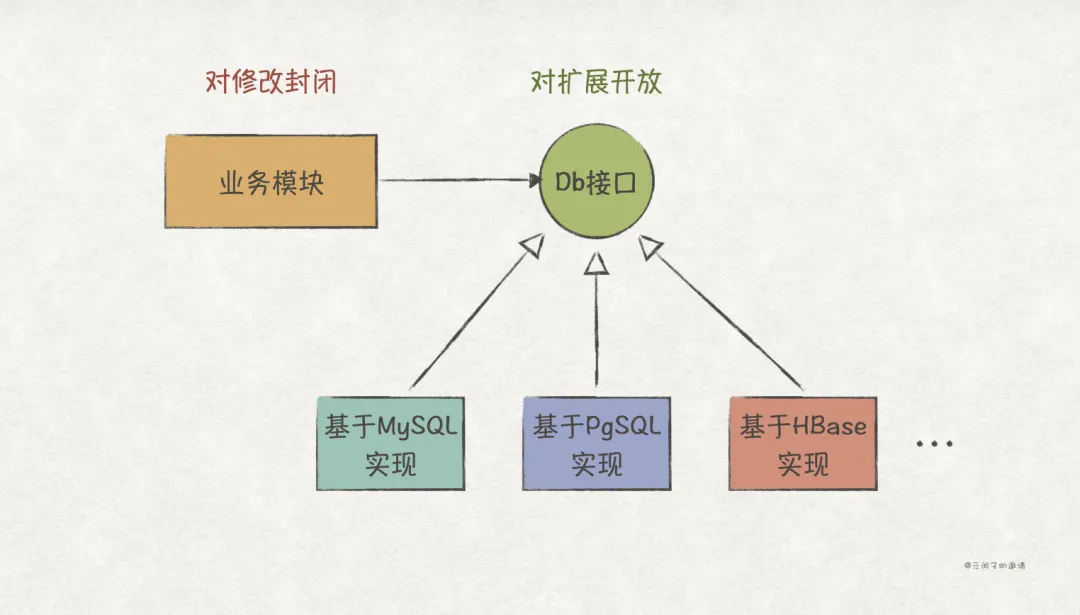
那么,在编程语言中,我们用什么来表示“数据库”这一抽象呢?是 接口 !
数据库最常见的几个操作就是CRUD,因此我们可以设计这么一个Db接口来表示“数据库”:
type Db interface {
Query(tableName string, cond Condition) (*Record, error)
Insert(tableName string, record *Record) error
Update(tableName string, record *Record) error
Delete(tableName string, record *Record) error
}这样,业务模块和数据库模块之间的依赖关系就变成如下图所示:
满足OCP的另一个关键点就是 分离变化 ,只有 先把变化点识别分离出来 ,我们才能对它进行抽象化。下面以我们的分布式应用系统demo为例,解释如何实现变化点的分离和抽象。
在demo中,监控系统主要负责对服务的access log进行ETL操作,也即涉及如下3个操作:
- 1)从消息队列中获取日志数据;
- 2)对数据进行加工;
- 3)将加工后的数据存储在数据库上。
我们把整一个日志数据的处理流程称为pipeline,那么我们可以这么实现:
type Pipeline struct {
mq Mq
db Db
...
}
func (p *Pipeline) Run() {
for atomic.LoadUint32(&p.isClose) != 1 {
// 1、从消息队列中获取数据
msg := p.mq.Consume("monitor.topic")
log := msg.Payload()
// 2、对数据进行字段提取操作
matches := p.pattern.FindStringSubmatch(log)
if len(matches) != 3 {
return event
}
record := model.NewMonitoryRecord()
record.Endpoint = matches[1]
record.Type = model.Type(matches[2])
// 3.存储到数据库上
p.db.Insert("logs_table", record.Id, record)
...
}
}现在考虑新上线一个服务,但是这个服务不支持对接消息队列了,只支持socket传输数据,于是我们得在Pipeline上新增一个InputType来判断是否使用socket输入源:
func (p *Pipeline) Run() {
for atomic.LoadUint32(&p.isClose) != 1 {
if inputType == input.MqType {
// 从消息队列中获取数据
msg := p.mq.Consume("monitor.topic")
log := msg.Payload()
} else {
// 使用socket为消息来源
packet := socket.Receice()
log := packet.PayLoad().(string)
}
...
}
}过一段时间,有需求需要给access log打上一个时间戳,方便后续的日志分析,于是我们需要修改Pipeline的数据加工逻辑:
func (p *Pipeline) Run() {
for atomic.LoadUint32(&p.isClose) != 1 {
...
// 对数据进行字段提取操作
matches := p.pattern.FindStringSubmatch(log)
if len(matches) != 3 {
return event
}
record := model.NewMonitoryRecord()
record.Endpoint = matches[1]
record.Type = model.Type(matches[2])
// 新增一个时间戳字段
record.Timestamp = time.Now().Unix()
...
}
}很快,又有一个需求,需要将加工后的数据存储到ES上,方便后续的日志检索,于是我们再次修改了Pipeline的数据存储逻辑:
func (p *Pipeline) Run() {
for atomic.LoadUint32(&p.isClose) != 1 {
...
if outputType == output.Db {
// 存储到DB上
p.db.Insert("logs_table", record.Id, record)
} else {
// 存储到ES上
p.es.Store(record.Id, record)
}
...
}
}在上述的pipeline例子中,每次新增需求都需要修改Pipeline模块,明显违反了OCP。下面,我们来对它进行优化,使它满足OCP。
分离变化点
根据pipeline的业务处理逻辑,我们可以发现3个独立的变化点
- 数据获取
- 数据加工
- 数据存储
进行抽象
我们对这3个变化点进行抽象,设计出以下3个抽象接口
// 数据获取抽象接口 type InputPlugin interface { plugin.Plugin Input() (*plugin.Event, error) } // demo/monitor/filter/filter_plugin.go // 数据加工抽象接口 type FilterPlugin interface { plugin.Plugin Filter(event *plugin.Event) *plugin.Event } // demo/monitor/output/output_plugin.go // 数据存储抽象接口 type OutputPlugin interface { plugin.Plugin Output(event *plugin.Event) error }基于扩展实现 Pipeline的实现如下,只依赖于InputPlugin、FilterPlugin和OutputPlugin三个抽象接口。后续再有需求变更,只需扩展对应的接口即可,Pipeline无须再变更
// ETL流程定义 type pipelineTemplate struct { input input.Plugin filter filter.Plugin output output.Plugin ... } func (p *pipelineTemplate) doRun() { ... for atomic.LoadUint32(&p.isClose) != 1 { event, err := p.input.Input() event = p.filter.Filter(event) p.output.Output(event) } ... }
总结
- OCP是软件设计的终极目标,我们都希望能设计出可以
新增功能却不用动老代码的软件。 - 但是100%的对修改封闭肯定是做不到的。
- 遵循OCP的代价也是巨大的。它需要软件设计人员能够根据具体的业务场景识别出那些最有可能变化的点,然后分离出去,抽象成稳定的接口。
- 这要求设计人员必须具备丰富的实战经验,以及非常熟悉该领域的业务场景。否则,盲目地分离变化点、过度地抽象,都会导致软件系统变得更加复杂
OCP总结
- 对扩展开放,对修改封闭
- 抽象的基础是接口
- 抽象的另一个关键点 : 分离变化
- 盲目地分离变化点、过度地抽象,都会导致软件系统变得更加复杂